MYSQL
分类:
| 分类 | 用途 | 具体实现功能 |
|---|---|---|
| DDL | 数据定义语言 | 用于定义数据库对象(数据库,表,字段) |
| DML | 数据操作语言 | 用于对数据库表数据进行增删查改 |
| DQL | 数据查询语言 | 用于查询数据库中表的记录 |
| DCL | 数据控制语言 | 用于创建数据库用户、控制数据库访问权限 |
约束:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制字段值不能为null | not null |
| 唯一约束 | 保证字段的数据唯一 | unique |
| 主键约束 | 主键是一行数据的唯一标识,非空且唯一 | primary key |
| 默认约束 | 若未规定该字段值,采用默认值 | default |
| 外键约束 | 让两张表的数据建立连接,保证数据的一致性和完整性 | foreign key |
check |
1 | |
数据类型:
数值类型:
字符串类型: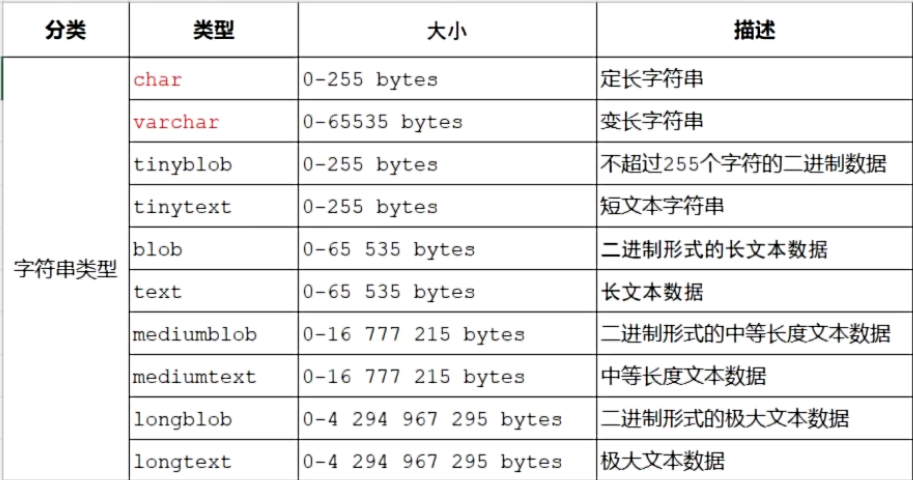
日期时间类型:
DDL(create,drop,alter…)
database等效于schema
库操作
- 查询所有数据库
show databases; - 查询当前数据库
select database(); - 使用/切换数据库
use 数据库名; - 创建数据库
create database [if not exists] 数据库名 [default charset utf8mb4]; - 删除数据库
drop database [if exists] 数据库名;
表操作
创建表:
1 | |
2
3
4
5
6
7
8create table user(
id int primary key auto_increment comment '用户id(唯一自动增长)',
username varchar(20) not null unique comment '用户名(非空唯一)',
password varchar(20) not null comment '密码(非空)',
name varchar(20) not null comment '姓名(非空)',
age int not null comment '年龄(非空)',
gender varchar(1) default '男' comment '性别(默认为男)'
)comment '用户表';
查询:
- 查询当前数据库的所有表
show tables; - 查询表结构
desc 表名; - 查询建表语句
show create table 表名;
修改:
- 添加字段
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束]; - 修改字段类型
alter table 表名 modify 字段名 新数据类型(长度); - 修改字段名与字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束] - 删除字段
alter table 表名 drop column 字段名; - 修改表名
alter table 表名 rename to 新表名;
删除:删除表drop table [if exists] 表名;
DML(insert,delete,update)
添加数据
- 指定字段添加数据
insert into 表名(字段名1,字段名2) values (值1,值2); - 全部字段添加数据
insert into 表名 values (值1,值2,...); - 批量添加数据(指定字段)
insert into 表名 (字段名1,字段名2) values (值1,值2),(值1,值2); - 批量添加数据(全部字段)
insert into 表名 values (值1,值2,...) (值1,值2,...);
修改数据
update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , ... [where 条件];
删除数据
delete from 表名 [where 条件];
DQL 查询语言
基本查询
- 查询多个字段:
select 字段1,字段2,字段3 form 表名; - 查询所有字段:
select * from 表名; - 为查询字段设置别名:
select 字段1 [as 别名1],字段2 [as 别名2] from 表名; - 去除重复记录:
select distinct 字段列表 from 表名;
FROM 表名 别名 或 FROM 表名 AS 别名(AS 是可选的)
UNION
UNION 用于将多个查询的结果合并成一个结果集。它会自动去除重复的行,返回唯一的结果。
1 | |
这条语句会将 table1 和 table2 中的 column1 和 column2 的结果合并在一起,同时去除重复的行。
UNION 和 UNION ALL 都可以用于合并查询结果,但它们的行为有所不同:
- **
UNION**:会自动去除重复的行。 - **
UNION ALL**:不会去除重复的行,会保留所有查询结果中的所有行,包括重复的行。
join
员工表(employees)
| emp_id | emp_name | dept_id | salary |
|---|---|---|---|
| 1 | 张三 | 101 | 5000 |
| 2 | 李四 | 102 | 6000 |
| 3 | 王五 | 101 | 4500 |
| 4 | 赵六 | 103 | 5500 |
部门表(departments)
| dept_id | dept_name | location |
|---|---|---|
| 101 | 技术部 | 3楼 |
| 102 | 市场部 | 5楼 |
| 104 | 人事部 | 2楼 |
INNER JOIN (内连接)
1 | |
| emp_name | dept_name | location |
|---|---|---|
| 张三 | 技术部 | 3楼 |
| 李四 | 市场部 | 5楼 |
| 王五 | 技术部 | 3楼 |
只返回两个表中dept_id匹配的行。赵六(dept_id=103)和人事部(dept_id=104)没有出现在结果中。
LEFT JOIN (左连接)
1 | |
| emp_name | dept_name | location |
|---|---|---|
| 张三 | 技术部 | 3楼 |
| 李四 | 市场部 | 5楼 |
| 王五 | 技术部 | 3楼 |
| 赵六 | NULL | NULL |
返回左表(employees)所有行,右表无匹配时显示NULL。赵六的部门103在部门表中不存在。
RIGHT JOIN (右连接)
1 | |
| emp_name | dept_name | location |
|---|---|---|
| 张三 | 技术部 | 3楼 |
| 李四 | 市场部 | 5楼 |
| 王五 | 技术部 | 3楼 |
| NULL | 人事部 | 2楼 |
返回右表(departments)所有行,左表无匹配时显示NULL。人事部没有对应的员工。
FULL JOIN (全连接)
1 | |
| emp_name | dept_name | location |
|---|---|---|
| 张三 | 技术部 | 3楼 |
| 李四 | 市场部 | 5楼 |
| 王五 | 技术部 | 3楼 |
| 赵六 | NULL | NULL |
| NULL | 人事部 | 2楼 |
返回两个表的所有行,无匹配的部分显示NULL。
子查询与多表查询
多表查询
1 | |
子查询
1 | |
条件查询
select 字段列表 from 表名 where 条件列表;
SQL 条件运算符:
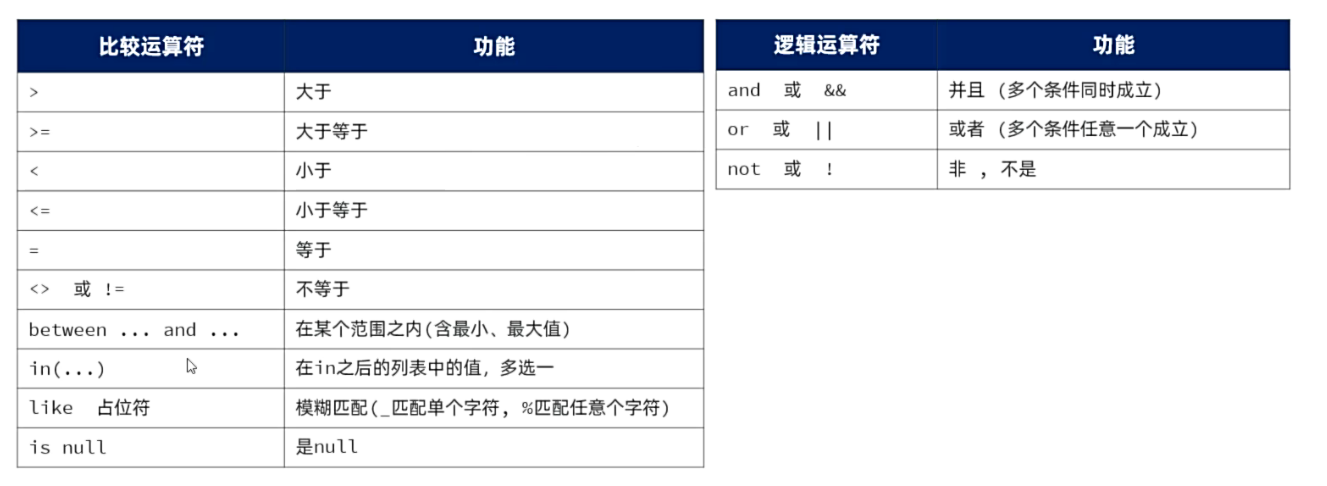
例:select * from user where job is not null
select * from user where name like '李_';姓名为李x的数据
select * form user where name like '%二%'姓名中包含二的数据
分组查询
select 字段列表 from 表名 [where 条件列表] group by 分组字段名 [having 分组后过滤条件];
where是分组前进行过滤,不满足where条件不参与分组,不能使用聚合函数,而having是分组之后对结果进行过滤
聚合函数
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
- 统计该表数据总数
select count(*) from emp;如果统计具体的字段数,值为null不参与统计 - 求一个字段的平均值
select avg(sorce) from emp; - 求一个字段的最小值
select min(sorce) from emp; - 求一个字段中的最大值
select max(sorce) from emp; - 求一个字段的总和
select sum(sorece) from emp;
select gender from emp group by gender进行分组操作后不要使用select *使用分组字段+聚合函数
select job.count(*) from emp where data <= '2015-01-01' group by job having count(*) >=2;挑选入职日期小于等于2015-01-01,筛选职位人数>2的职位
排序查询
select 字段列表 from 表名 [where 条件列表] [group by 分组字段名 having 分组后过滤条件] order by 排序字段 排序方式;
升序(asc) ,降序(desc),默认升序
select * from emp where data <= '2015-01-01' order by data desc
select * from emp where data <= '2015-01-01' order by data, update desc;
分页查询
select 字段 from 表名 [where 条件] [group by 分组字段 having 过滤条件] [order by 排序字段] limit 起始索引,查询纪录数;
- 起始索引从0开始
- 分页查询是数据库的方言,不听数据库有不同的实现,MYSQL种是LIMIT
- 如果起始索引为0,每页展示10条数据
limit 0,10起始索引可以省略,简写为limit 10
select * from emp limit 0,5;查询数据,每页展示五条数据
select * from emp limit 5,10;查询第二页数据,每页展示五条数据
$起始索引=(页码-1)*每页展示记录数$
DCL数据控制语言
GRANT
GRANT 权限列表 ON 数据库对象 TO 用户 [WITH GRANT OPTION];
1 | |
REVOKE
REVOKE 权限列表 ON 数据库对象 FROM 用户;
1 | |
1 | |
视图
用于有些数据需要频繁的查询
视图是一个虚拟表,基于 SQL 查询的结果集。它不存储实际数据,而是动态地从基表(物理表)中获取数据。
看起来是创建了一个新表,但本质上是记录了sql语句,当查询视图时,本质上执行了视图相关的sql语句
1 | |
查询视图
1 | |
视图的更新限制
- 可更新视图:满足以下条件时,可以通过视图修改基表数据:
- 视图基于单表(无
JOIN)。 - 不包含聚合函数、
DISTINCT、GROUP BY等操作。
- 视图基于单表(无
- 不可更新视图:涉及多表关联或聚合操作时,无法直接通过视图修改数据
索引
索引是数据库中加速数据检索的数据结构(如 B-tree、哈希表)。它类似于书籍的目录,通过预排序或哈希映射快速定位数据。
常见索引类型:
| 索引类型 | 适用场景 | 特点 |
|---|---|---|
| B-tree | 范围查询(如 WHERE age > 18) |
支持排序、范围查询,通用性强 |
| 哈希索引 | 精确查询(如 WHERE id = 100) |
查询极快,不支持范围查询 |
| 全文索引 | 文本搜索(如 LIKE '%keyword%') |
优化文本模糊匹配 |
| 复合索引 | 多列组合查询 | 按列顺序匹配查询条件 |
2. 索引的创建与使用
语法:
1 | |
示例:
在 orders 表的 customer_id 列上创建索引:
1 | |
查询优化效果:
1 | |
3. 索引的优缺点
- 优点:
- 显著提高查询速度(尤其是大数据表)。
- 加速
JOIN和ORDER BY操作。
- 缺点:
- 占用额外存储空间。
- 增删改操作变慢(需维护索引)。
原理举例
1. 无索引的查询(全表扫描)
假设有一张 users 表(100 万行数据),执行以下查询:
1 | |
- 操作流程:
数据库会逐行扫描所有 100 万条记录,检查每行的email是否符合条件。 - 时间复杂度:O(N)(线性时间),数据量越大越慢。
2. 有索引的查询(B-tree 索引)
在 email 列上创建索引:
1 | |
再次执行相同查询:
- 操作流程:
- 数据库使用 B-tree 索引(一种平衡树结构),快速定位到
email = 'zhangsan@example.com'的存储位置。 - 直接读取对应的数据行(通常只需几次磁盘 I/O)。
- 数据库使用 B-tree 索引(一种平衡树结构),快速定位到
- 时间复杂度:O(log N)(对数时间),速度极快。