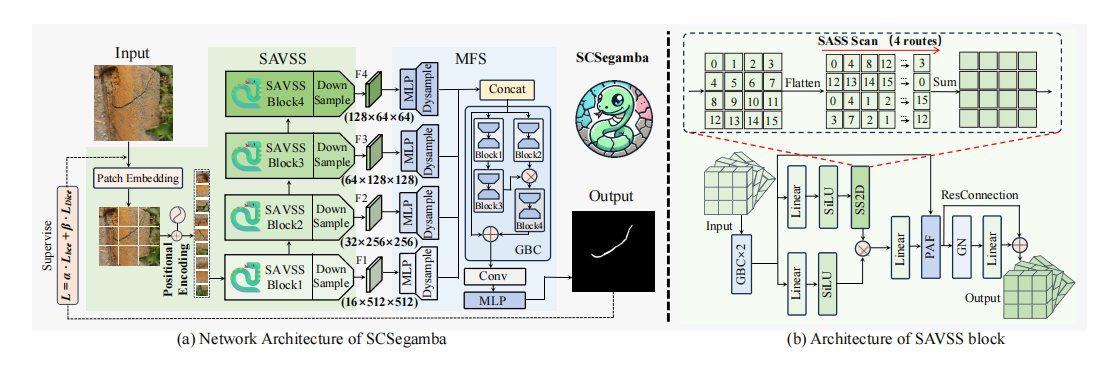
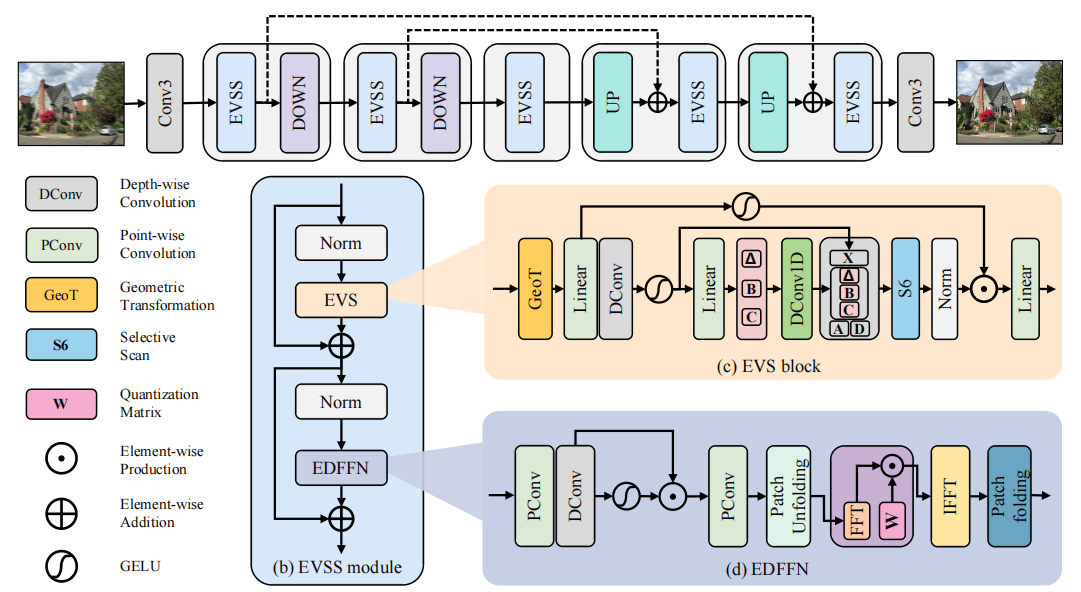
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
class Decoder(nn.Module):
def __init__(self, backbone, args=None):
super().__init__()
self.args = args
self.backbone = backbone
embedding_dim = 8
self.linear_c4 = MLP(input_dim=128, embed_dim=embedding_dim)
self.linear_c3 = MLP(input_dim=64, embed_dim=embedding_dim)
self.linear_c2 = MLP(input_dim=32, embed_dim=embedding_dim)
self.linear_c1 = MLP(input_dim=16, embed_dim=embedding_dim)
self.GBC_C = GBC(embedding_dim*4)
self.linear_fuse = BottConv(embedding_dim*4, embedding_dim, embedding_dim//8, kernel_size=1, padding=0, stride=1)
self.DySample_C_2 = DySample(embedding_dim, scale=2)
self.DySample_C_4 = DySample(embedding_dim, scale=4)
self.DySample_C_8 = DySample(embedding_dim, scale=8)
self.embedding_dim = embedding_dim
self.deffn = EDFFN(dim=embedding_dim, ffn_expansion_factor=2.66, bias=False)
self.dropout = nn.Dropout(p=0.1)
self.linear_pred = BottConv(embedding_dim, 1, 1, kernel_size=1)
self.linear_pred_1 = nn.Conv2d(1, 1, kernel_size=1)
def forward(self, samples):
outs_SAVSS = self.backbone(samples)
c4, c3, c2, c1 = outs_SAVSS
b, c, h, w = c4.shape
out_c4 = self.linear_c4(c4.reshape(b, c, h*w).permute(0, 2, 1)).permute(0, 2, 1).reshape(b, self.embedding_dim, h, w)
out_c4 = self.DySample_C_8(out_c4)
b, c, h, w = c3.shape
out_c3 = self.linear_c3(c3.reshape(b, c, h*w).permute(0, 2, 1)).permute(0, 2, 1).reshape(b, self.embedding_dim, h, w)
out_c3 = self.DySample_C_4(out_c3)
b, c, h, w = c2.shape
out_c2 = self.linear_c2(c2.reshape(b, c, h*w).permute(0, 2, 1)).permute(0, 2, 1).reshape(b, self.embedding_dim, h, w)
out_c2 = self.DySample_C_2(out_c2)
b, c, h, w = c1.shape
out_c1 = self.linear_c1(c1.reshape(b, c, h*w).permute(0, 2, 1)).permute(0, 2, 1).reshape(b, self.embedding_dim, h, w)
out_c = self.GBC_C(torch.cat([out_c4, out_c3, out_c2, out_c1], dim=1))
out_c = self.linear_fuse(out_c)
out = self.deffn(out_c)
out = self.dropout(out)
out = self.linear_pred_1(self.linear_pred(out))
return out
|